




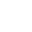


本文是笔者在北邮AI协会(BUPT AI ML Club, ai-ml.club)的第3季第12次例会上的论文分享记录。在本次例会上,笔者介绍了由滑铁卢大学计算机学院的S. Keshav总结的阅读论文的一系列技巧[1],以及笔者关于这些技巧的心得体会。
论文的大数据时代
身为一个研究者,我们每天都可能要在ArXiv、Google Scholar或者其他的论文发布平台上面对数十甚至数百篇论文,以跟进领域的前沿动态与最新进展。在阅读每一篇论文的时候,又会在内容上画下数不尽的记号,以标明其中每个部分的重要性。无数的论文和记号,最终构成了我们所拥有的论文大数据。
如果将大数据中的每篇论文看做主节点,每个记号看做次节点,这些论文和记号就结成了网,形成了大数据的知识图谱。既然知识图谱的规模非常庞大,尽量减少冗余信息,提升检索效率就成了不得不探讨的议题。因此,如何从一篇论文中提取出最核心、最主要的内容的问题显得尤为重要。

设想一下,如果论文本身就可以被看做数据的话,它的特征应该是什么?最简单的方法应该是把论文视为一张图片,训练一个像VGGNet、ResNet等结构的卷积网络去发现其中最具判别性的部分。对于人类来说,这个部分可能是标题、摘要或者插图等等。那么对于机器来说呢?

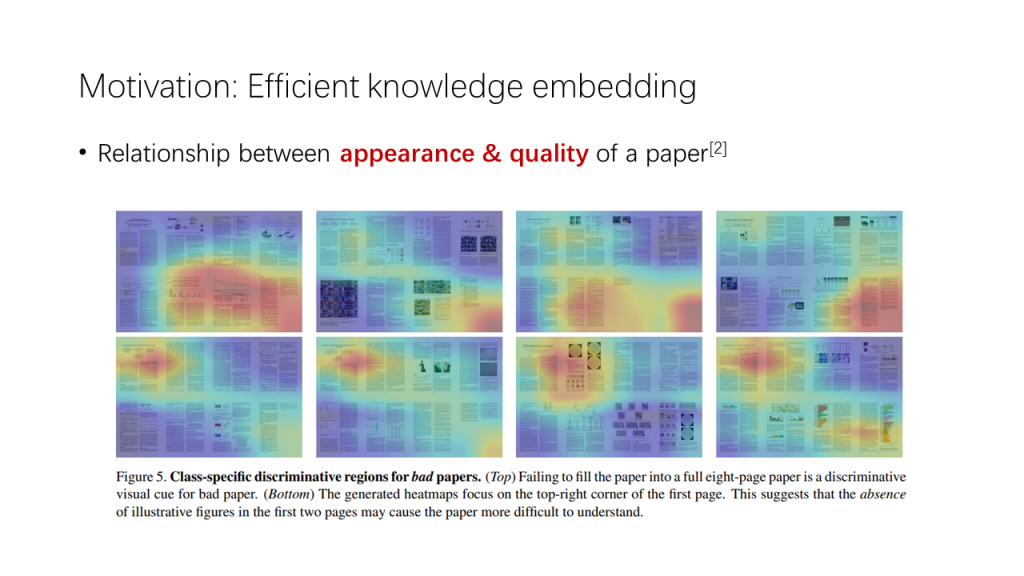
曾有研究者做过这样的研究[2]:把计算机视觉顶级会议CVPR的历届会议的会议论文(Conference Paper)与讲习班论文(Workshop Paper)收集起来,将会议论文看做质量“好”的论文,将讲习班论文看做质量“差”的论文,通过这样的监督信号,训练网络对论文进行二分类。
当然,作者也解释说这样的监督信号并不是完美的,因为并不是所有的讲习班论文都是被会议淘汰下来的。但讲习班论文与会议论文之间的平均质量差距已经得到研究社群的公认,因此这样的估计从一定程度上来说也是合理的。
研究者在结论中指出,训练之后的网络能够自动发现论文中具有判别性的特征,并找出一篇论文被评为“差”论文的原因,如论文篇幅没有完全填充八页,或者没有一个很好的封面图指引读者了解文章的概要。从这个角度看,机器也能发现人类看论文的一些潜在因素:“颜值”。但从人类读者的角度而言,在“颜值”筛选之外,还应该有更多的筛选标准以辅助判断,否则对于那些公式很多但配图寥寥的“神作”,我们就很可能会轻易错过。
“三步走”策略
S. Keshav提出了一个“三步走”策略,以概括阅读论文时提取内容的不同层次及对应的提取方法。具体而言,在第一个阶段,应该通过文章中的一些基本线索,如大小标题、参考文献等对论文的基本情况有大概的认识;在第二个阶段,决定了深入研读之后,应该向论文中的“硬骨头”,如实验结果、理论细节等下手,掌握论文的核心内容;在最后一个阶段,应该更深入地理解论文,并找到其中可以改进或创新的部分,获得自己的专有知识。
事实上,我们可以从深度学习的实践中找到这种方法的缩影。对于一个视觉物体分类问题,我们一般以一个较高的学习率作为开始,鼓励网络去学习数据集中的一般规律,亦即数据集的“大致情况”,得到的结果则是一些基础的视觉滤波器,虽然能够捕捉低级特征,但无法提供强大的判别性。
而随着学习过程的逐步推进,我们逐渐降低学习率,让网络学习更多的细节,掌握数据集的“核心内容”(在度量学习中也被称为难样本),并获得更强大的判别性;如果网络被用在不同于一般物体分类的任务上,我们还可以使用指定任务的数据集进行迁移学习,获得特定于任务的专有知识。这样的学习模式和阅读论文的模式是不谋而合的,这为我们理解深度网络和人的行为相似性也提供了一个典型的案例。
第一步:放眼全文
第一步的主要目的是对论文的基本情况有一个大概的认识。这不禁让我联想到成年人的相亲:许多的成年人,互相以自身的职业、年龄、收入等作为标签,等待异性以一个评判者的身份出现,通过这些基本的情况判断自己作为伴侣的质量分数。事实上论文也是同理。
标题、摘要和封面图
回想一下,当我们第一次看到一篇论文的时候,映入眼帘的是什么呢?没错,当然是标题、摘要和封面图(特指论文中总括全文的第一张图片)了。标题是吸引读者点开文章的招牌,摘要是一言以蔽的向导,而封面图则是一图了然的海报。从标题中,我们可以获得论文可能涉及的领域和方法;从摘要中,我们可以了解论文所研究问题的前因后果;从封面图中,我们可以了解领域中解决问题的一般方法,并发现作者的不同之处或是创新点。
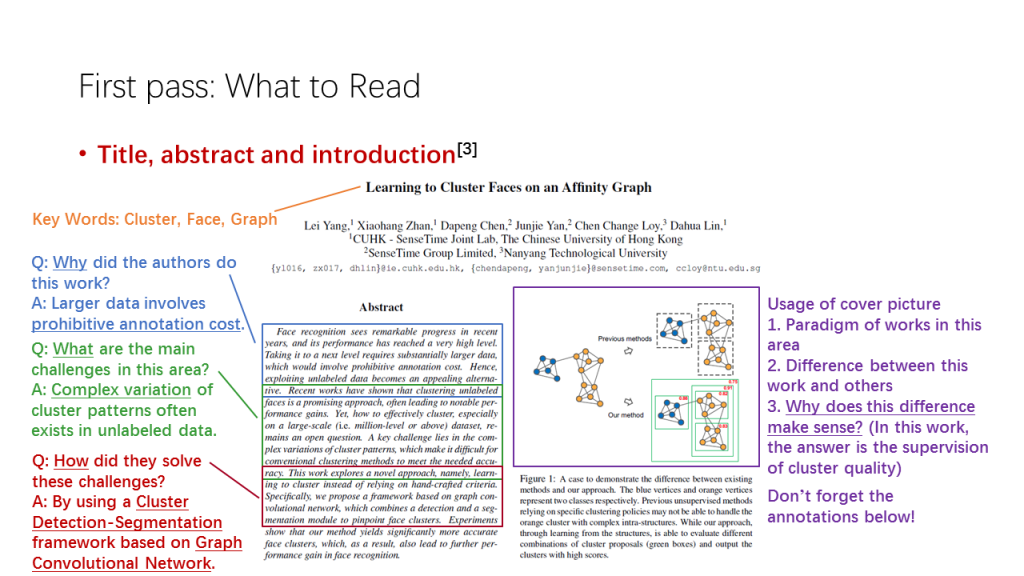
我们以CVPR2019 Oral的一篇论文Learning to Cluster Faces on an Affinity Graph[3]为例。
从标题中,我们不难捕捉到Cluster, Face, Graph三个主要关键词,了解到本文可能涉及了人脸与聚类算法两个领域,主要的解决方法是基于图的聚类。
而从摘要中,我们可以得知这项研究工作的起因,是大数据的标注成本较高,需要一种半自动的方式进行标签传播,用尽可能少的人工标签实现数据标注;遇到的主要挑战,是复杂多变的聚类模式 (如长尾分布) 使得朴素的聚类方法难以适用;而该论文解决挑战的方法,则是使用了基于图卷积网络的聚类检测-分割框架。
封面图的使用牵涉到了更多的论文细节,本文的封面图通过图的节点颜色、质量分数等一系列要素说明,过去的朴素聚类方法无法解决很好地解决复杂多变的类内结构,而基于图的聚类不仅基于层次,也能够对聚类的质量进行判断,从而留下可能性更高且更全面的聚类。特别要注意的是,为了进一步地理解封面图的具体含义,对该图的文字注释进行仔细阅读也是必要的。
小节的标题
在强调完第一页若干要素的重要性后,作者指出,接下来需要注意的应该是各小节的标题。对于小节标题较多的Methodology与Experiments部分而言,小节标题的归纳尤为重要。
如图,对于本文的Methodology,如果我们把每个小节的标题看做一个函数的“声明”,那么各小节综合起来,就构成了函数的层级调用结构。不同小节的方法之间有顺序关系,就构成了Methodology的一个流水线(pipeline,类似于主函数main)。这就像大型软件工程中的代码,在主函数的具体定义之前,会有头文件来定义主函数所需要调用的函数接口,而论文中小节的标题的综合就对应了头文件的内容。因此,对小节标题的归纳有助于读者对方法流程和实验过程的基本了解,从而带着新的问题去阅读更多的细节。

数学性内容
数学性内容同样也不可或缺。对算法、公式的浏览有助于了解论文提出的方法和自己的知识基础之间的关系,如本文的Algorithm 2就和朴素聚类方法中的层次聚类法有所关联。
与此同时,笔者认为对理论容量的审视同样能够对论文的质量估计形成有效的辅助。(以下是笔者的一个猜想,不代表作者观点)在相当一部分论文中,如果理论容量过大而实验性能不足,则应当怀疑其部分理论在实验场景下的必要性或正确性。这是出于理论和实验一致性的考虑,即实验性能应该能匹配理论的充分或复杂程度。同样地,实验强而理论弱的结果也应该被质疑实验的正确性,除非有限的理论足以解释造成实验结果的原因。

总结与参考文献
第一步的最后应该注意的是总结与参考文献。在阅读了许多与方法和实验相关的描述之后,我们很容易只见木不见林,在其中一些小的环节上got stuck,总结能够让我们快速跳出这个局部最小值,对论文的主要贡献做一个鸟瞰式的回顾,并思考论文整体与自己的研究之间的联系。
作者特别指出,参考文献的阅读方式应该是将自己阅读过的文献一一筛去,留下没有阅读过的文献。尽管尚未阅读的文献可能占据了大多数,但记录这些文献的索引,有利于对所阅读的论文在领域中所处的上下文有一个基本的认识,从而更好地把握整个领域的发展脉络。

5C策略
在阅读的第一遍结束之后,读者已经对论文的基本情况有了一个大概的了解。为了对这些基本情况进行分门别类的处理,作者提出了“5C策略”,从论文的分类、贡献、上下文、正确性与清晰性五个角度对论文进行评价。
- 分类:不同分类的论文,写作方式是并不相同的。如评估类文章,写作要点就应集中在不同参数对实验结果的不同影响上;而对于研究原型类文章,则应该着重强调研究的理论框架。对论文进行分类,有利于在再次阅读时有所侧重地分配时间,而非东一榔头西一棒槌式的泛读。
- 贡献:对论文实际贡献的归纳,能够促使读者进一步思考论文对其所研究的领域,乃至自己所研究问题的作用,并带着思考中的收获与困惑进一步阅读论文。
- 上下文:论文在领域中所处的地位也至关重要。如果延续前言中我们作的“知识图谱”假设,我们应该在阅读过程中对知识图谱中的那些“核心节点”赋予较高的权重,而对“边缘节点”赋予较低的权重。换言之,如果一个研究工作至关重要,对于这项工作的“地基”则应更加侧重。
- 正确性:尽管有时实验结果可能令人极其满意,论文假设、结论等内容的正确性仍然是值得讨论与怀疑的一点。在笔者为期不长的科研生涯中,就曾遇见过两篇论文实验结果可以相互媲美,但结论完全相反的情况。因此在第一遍通读过后,重新审视论文的主要假设与结论,或许有时会有不一样的发现。
- 清晰性:如果在阅读过程中发现了作者表意不清、符号混乱、错字连篇等无法让读者对文章内容作进一步理解的情况,应当着重标注。如果囿于这样的错误中,很可能对论文本身要提供的信息产生误解,而阻碍进一步的研究。 除此之外,作为研究者,我们既是他人论文的审读者,也是自己论文的撰写人。多发现他人的错误,也可以为自己的正确写作提供必要的借鉴。

在下一步之前
在第一次通读全文并进行思考过后,读者有权选择继续阅读这篇论文还是放弃。对于那些没有进一步的探讨价值,或是存在自身问题的论文,读者大可不必在此浪费时间(探讨阅读论文技巧的目的正是为了最大化地利用时间)。但在此之前,读者应该给出一个能够说服自己的具体理由,如不能引起兴趣、逻辑不清晰等,并以之为反例来修正自己的研究工作,如形成一个合适的篇章结构,采用更好的理论工具等。
当你凝视着深渊的时候,深渊也在凝视着你。
——尼采《善恶的彼岸》

第二步:攻坚克难
到了第二步,我们更应该关注那些在第一步忽略掉的“硬骨头”与更多的细节问题。在深度学习中这对应着更难下降的损失函数,和更低的学习率。
方法的性能表现
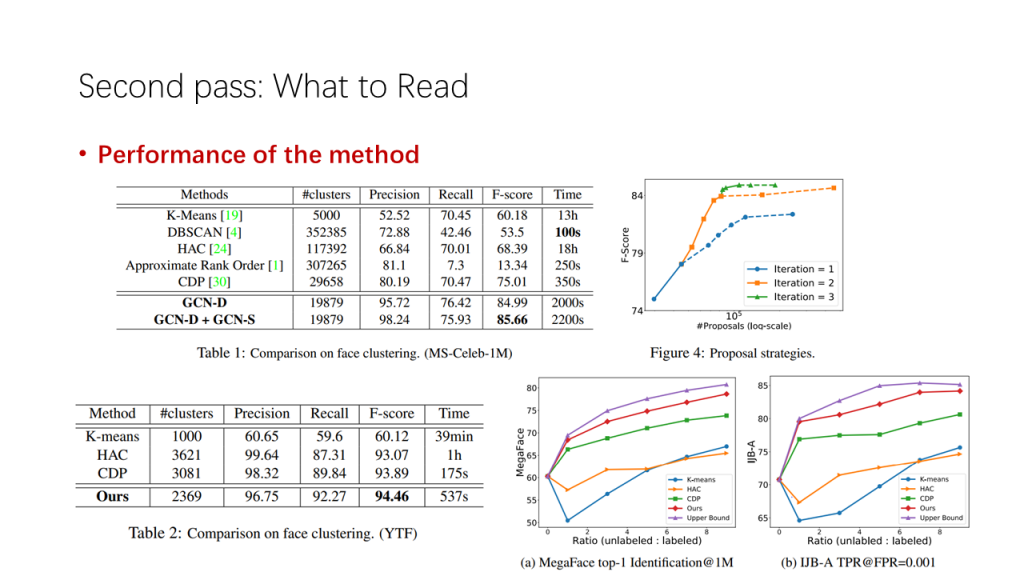
很遗憾,S. Keshav在文章中没有具体指出这些细节是什么。但作为计算机科学,一个以实践为主要目标的研究者,笔者认为我们首先应该关注的是实验部分。其原因是,在日新月异,迭代迅速的计算机领域,如果方法的性能表现落后于主流水平,就很容易被快速淘汰。因此,通过对方法的性能表现的了解,我们能够对方法在领域中所处的技术水平有更深入的认识。
方法的具体细节
对论文实际方法的掌握堪称啃下整篇论文的“硬骨头”。笔者比较推荐的一种方法是,依据前文提取的小标题,通过阅读细节的文字不断补充和完善对应的内容。如果说在第一步中我们定义了论文方法的接口,那么现在我们正是在补充函数的具体内容。也正是因此,在算法流程出现比较多的计算机科学,我们可以把自己模拟成计算机,仿照程序的执行流程与函数相互调用过程,来达到完善程序细节的目的。

当然,为了不落入理论证明的迷宫中,还是应该忽略证明的细节。作为第二步,读者应该去掌握应用方法的更多细节,而非去探究方法的理论支撑是否坚实。

发现不解之处
在阅读实验与方法细节的过程中,难免会遇见自己对某个符号,或某些基础理论不理解的情况。如果这种情况很多,那么读者将要面对的可能就是一个全新的世界。尽管进一步探索也要付出时间的代价,但记录下这些无法理解的只言片语,或许也能在某个时候提供意想不到的裨益。

在下一步之前
如此我们便完成了第二步的阅读。由于第一步的概要性阅读为第二步的攻坚克难做了大量的铺垫,第二步比想象中要来得轻松。(Congratulations!) 但现在可不是放松的时候,在阅读了大量的细节之后,读者应该及时记下对自己所理解的内容的想法,以及自己所无法理解的其他内容,为第三步的实际应用打好思想与理论上的基础。

第三步:举一反三
到了最后一步,读者已经对论文的细节和实际应用方法有了全面的认识。在这些知识基础的驱动下,读者应该自行在思想上甚至实践上去复现整套方法,以发现其中潜在的问题与创新点。
仍旧以CVPR2019的这篇文章为例。笔者尝试着分析其中的Algorithm 2,并在分析过程中发现了一个重要的问题:如果提取特征的模型在训练数据上过拟合了,所得到的聚类建议就都是高质量分数的,这样的聚类建议用来训练图卷积网络便会导致正类大于负类的数据偏置。随后笔者带着这样的疑问私信了该文作者,得到了肯定的答复。

值得注意的是,尽管从实践上复现论文是很有必要的,但由参数不对或是缺乏必要的但论文没有叙述的技巧而导致的无法复现的例子比比皆是。因此对于时间不够充裕的读者,这一项仍应作为可选(optional)而存在。

三步走的内在哲理
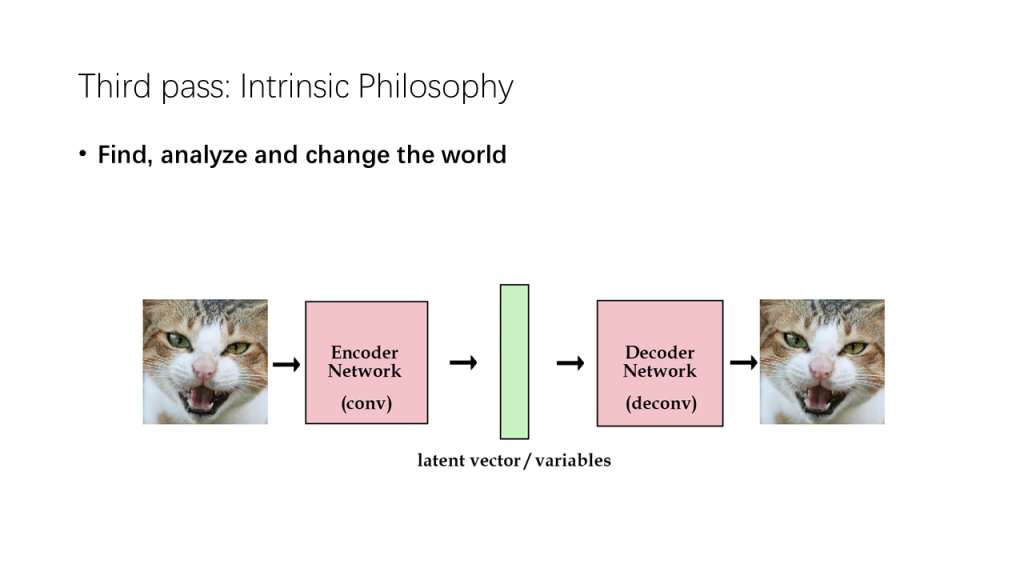
事实上,刚才提到的三步走策略和深度学习中的自编码器(Autoencoder)结构有异曲同工之妙。如果仔细观察它们的话,会发现它们都是一个发现规律、认知规律并改造规律的过程,自编码器的规律是图像的流形,而三步走策略的规律则是论文的谋篇布局与具体内容,这或许也印证了人类科技发展中亘古不变的这条真理。
应用:文献调研
在之后的文字中,作者还给出了对于研究生做文献调研的一些建议。这些建议也和之前介绍的论文阅读技巧高度相关。
搜索引擎
工欲善其事,必先利其器。尽管Google Scholar, ArXiv这种在线检索平台在学术界可谓人尽皆知,作者仍然不忘记强调它们在文献调研中扮演的重要角色,可见具备一个这样的综合型资料检索平台对研究工作效率的提升程度。
领域综述
在拥有了适当的搜索工具之后,搜索的具体内容就被纳入了讨论范畴。一个比较简单直接的方法是找到这个领域颇负盛名的一篇综述论文,顺着作者对领域从宏观到微观的理解,逐步梳理其发展脉络。一篇好的综述论文应该面面俱到,详略得当,作者常读的综述[4]就正符合这两点。从事其他方向的读者们也不妨参照这篇论文,去寻找与自己领域相关的综述论文。

重要论文
另一个比较粗暴但有效的方法是从知识图谱的“边缘节点”出发,寻找与“边缘节点”们同时接近的“核心节点”,也就是找到被其他论文高度引用的论文。引用量大的论文一般在学术界影响深远,并最终构成了领域知识的一些主要部分。对一个“核心节点”的掌握,就有可能触发更多的“节点”,从外而内地建立起大的图谱网络。

前沿研究
尽管目的是调研文献,也不能忽略了前沿的研究。前沿研究是领域的风向标,左右着领域未来的发展方向。因此,将前沿研究包含进自己的文献调研中,有助于发现领域自身存在的边界,从而对领域的瓶颈问题有更深入的理解。就计算机领域而言,读者应该随时跟进前沿顶级会议(如题主所从事的计算机视觉的CVPR, ICCV, ECCV),将这些会议中和自己领域有关的部分包含进来,作为前沿研究的最新成果而展示。
参考文献
- [1] S. Keshav. How to Read a Paper. David R. Cheriton Schoool of Computer Science, University of Waterloo Canada, keshav@uwaterloo.ca
- [2] Jia-Bin Huang. Deep Paper Gestalt: arXiv preprint arXiv: 1812.08775, 2018.
- [3] L. Yang, X. Zhan, D. Chen, J. Yan, C. C. Loy, and D. Lin. Learning to cluster faces on an affinity graph. In CVPR 2019.
- [4] M. Wang and W. Deng. Deep visual domain adaptation: A survey. arXiv preprint arXiv:1802.03601, 2018.

